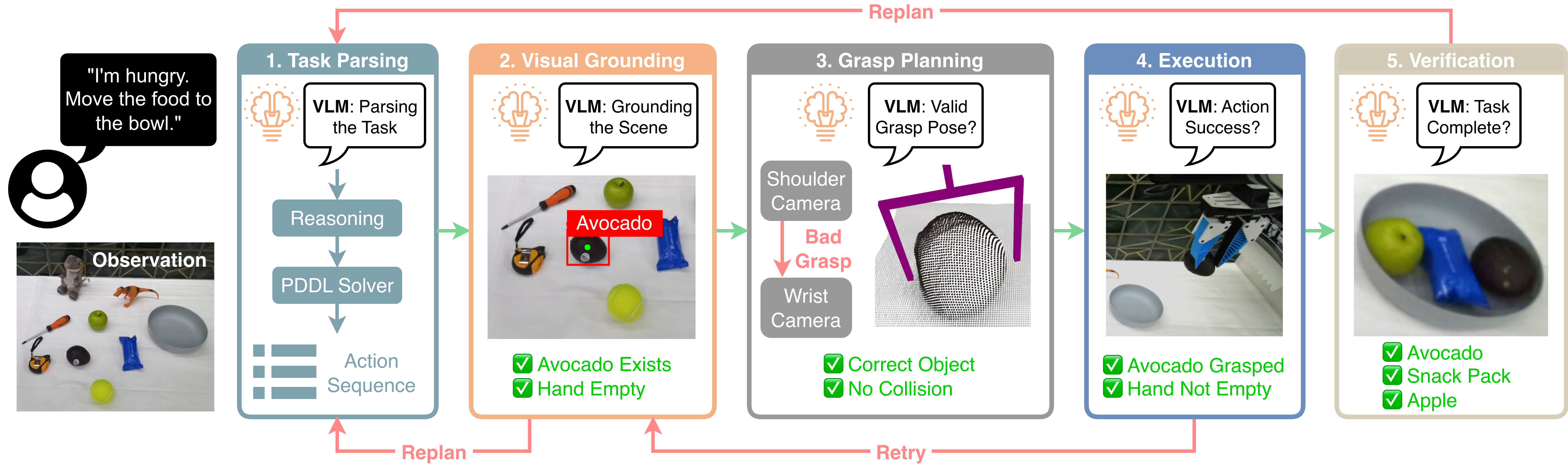
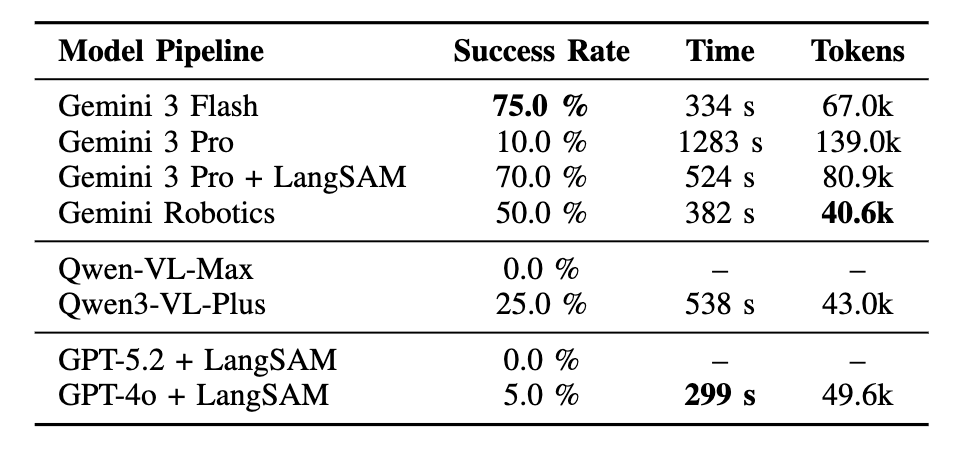
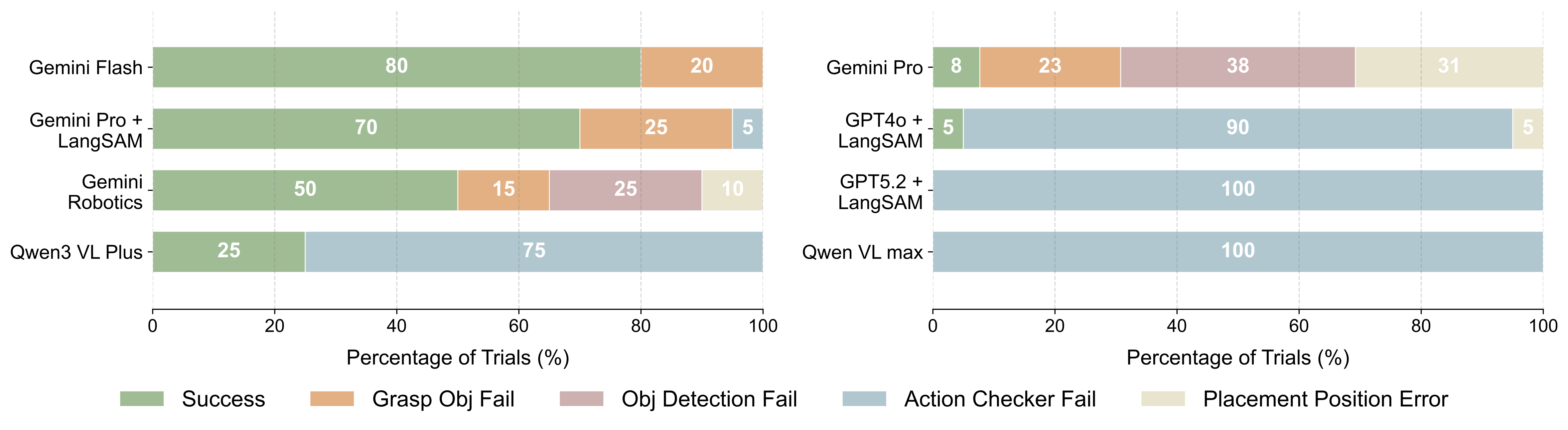
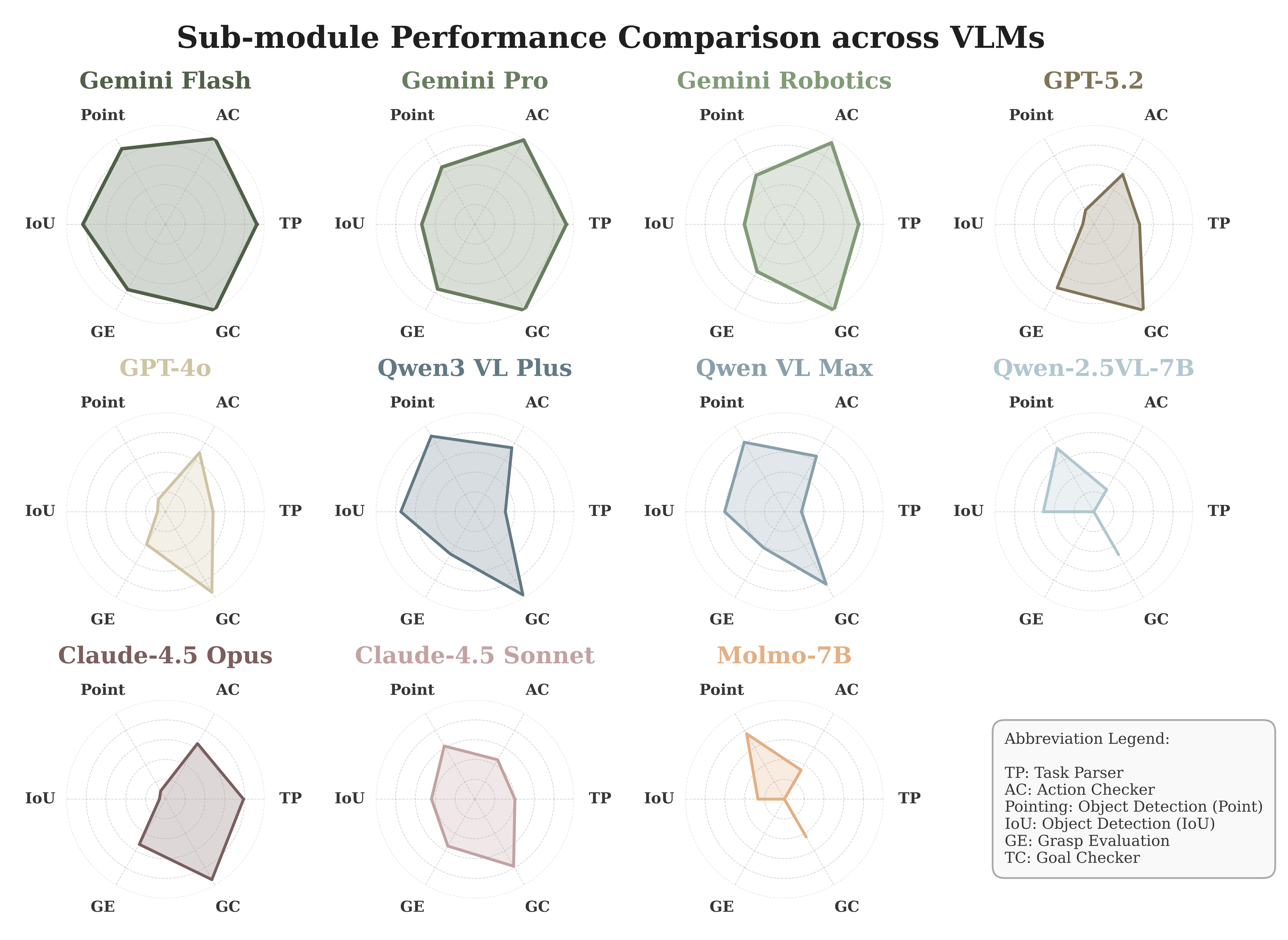
AgenticLab: A Real-World Robot Agent Platform
that Can See, Think, and Act
1Purdue University
2Instituto Italiano di Tecnologia
*Equal contribution
 The full hardware–software stack of AgenticLab will be released.
The full hardware–software stack of AgenticLab will be released.